|
Hi, I am currently a second year PhD student in computer science at the Courant Institute at New York University advised by Professor Chen Feng. My First name in Chinese is 觉晓. It comes from a famous poem in Tang Dynasty (618-907 AD), which depicts a quiet spring morning. I also go by my English nickname Jeremy. Previously, I obtained my Bachelor's degree in EE from Tsinghua University and my Master's degree in CS from NYU. During my Master's I was fortunate to work with Prof. Chen Feng AI4CE Lab on scene representation for robotics and Dr. Yubei Chen on unsupervised representation learning. I am interested in learning scene representations that are useful for robots to understand the world and interact with it. Email / LinkedIn / Google Scholar / Github |

|
|
New York University,
Ph.D in Computer Science, 2023 - present
|
|
Samsung Research America, 2025 | Research Intern | Text-to-Image Generation, Host: Dr. Luowei Zhou |
|
|
|
💡Lead & major contributions✨ (first/co-first/project lead/second author). |
|

|
Irving Fang*, Juexiao Zhang *†, Shengbang Tong, Chen Feng, (* for equal contribution, † for project lead) Under review arXiv / Project Page / Code / HuggingFace When building a VLA from VLMs, how much generalization power can it get? |
|
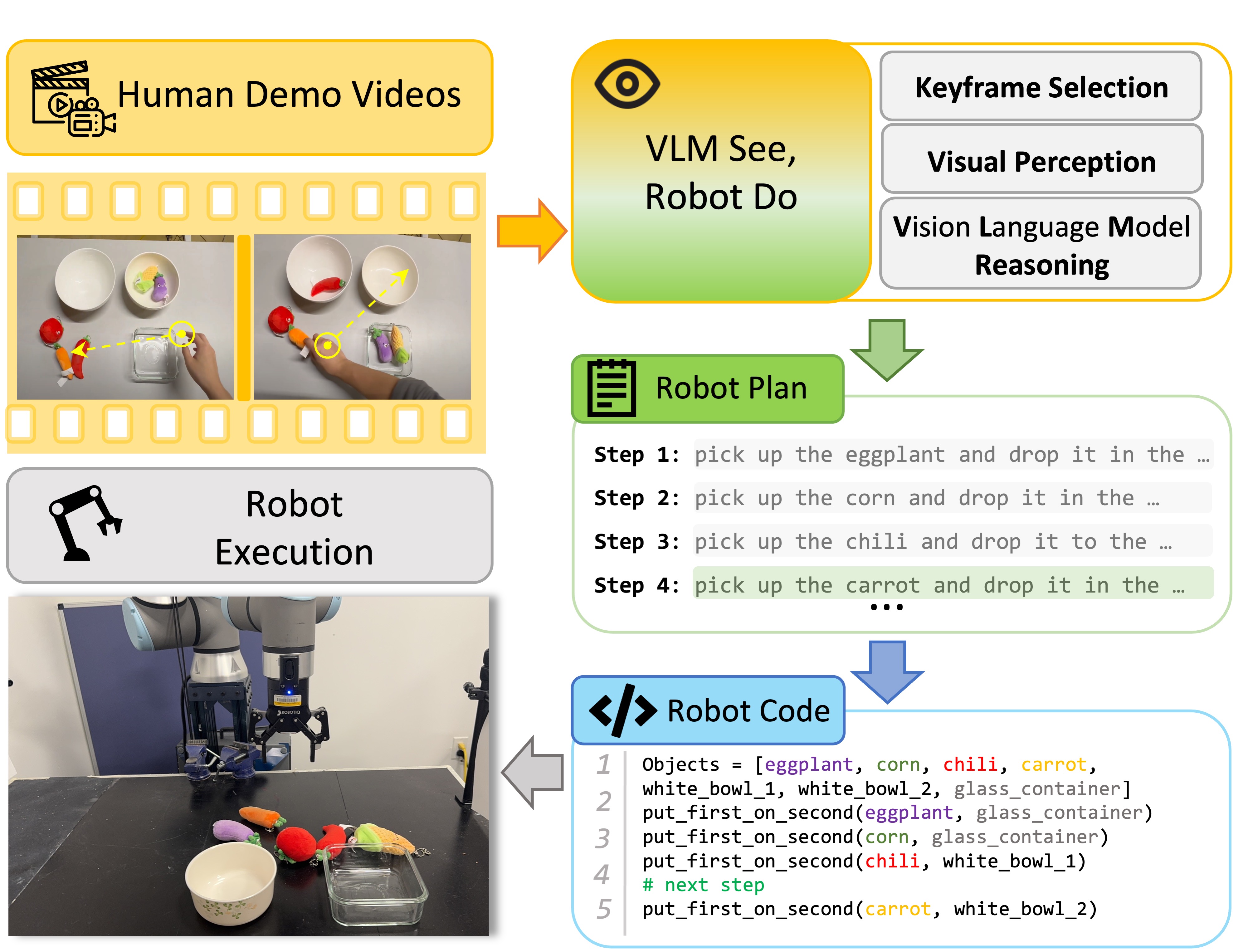
Beichen Wang*, Juexiao Zhang*, Shuwen Dong†, Irving Fang†, Chen Feng (*† for equal contribution) IROS 2025 arXiv / project page / code Let the robot follow a human's actions by just watching one video. |
|
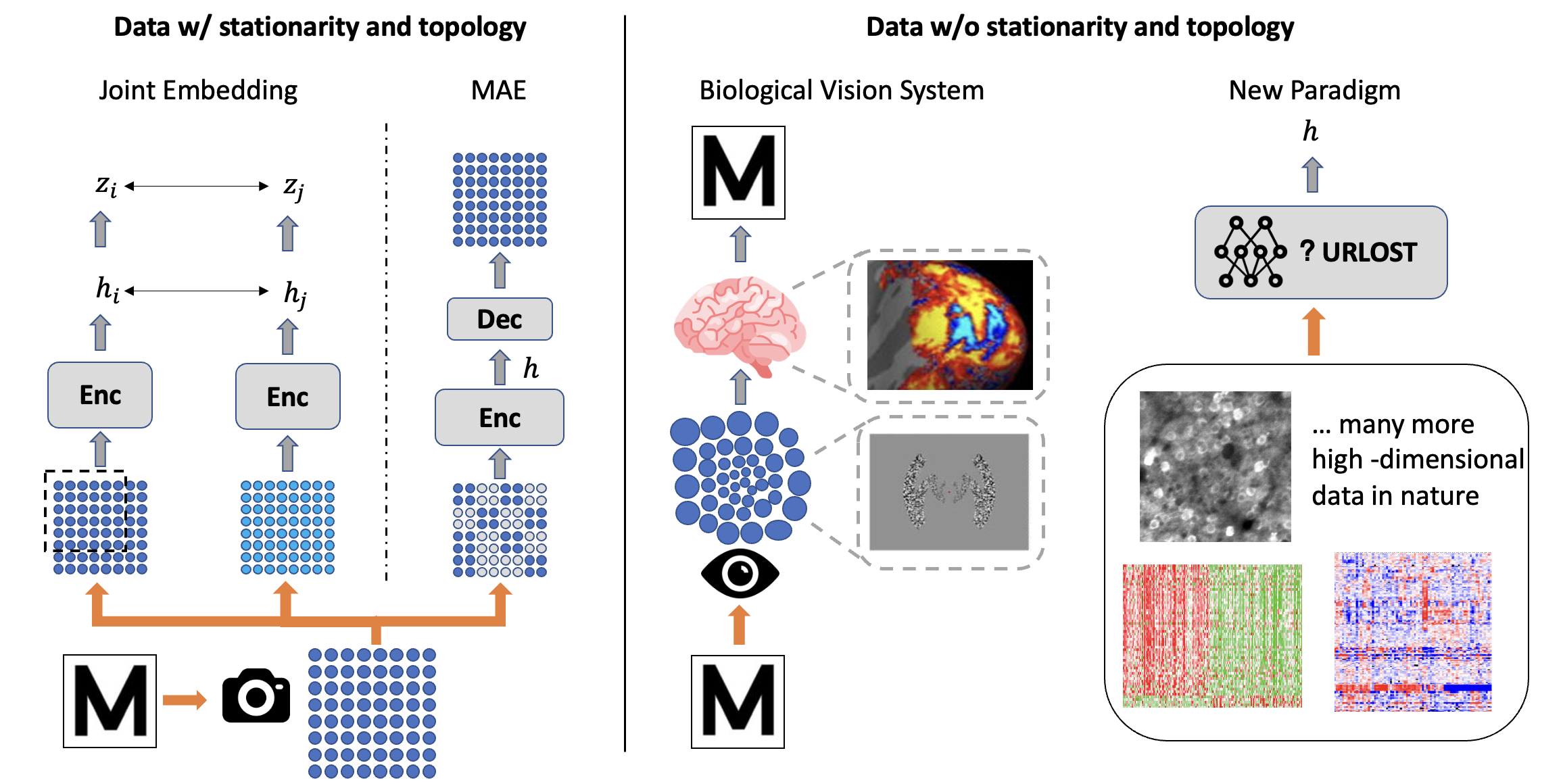
Zeyu Yun, Juexiao Zhang, Yann LeCun, Yubei Chen ICLR 2025 arXiv An unsupervised representation learning for high-dimensional data without explicit stationarity and topology. |
|
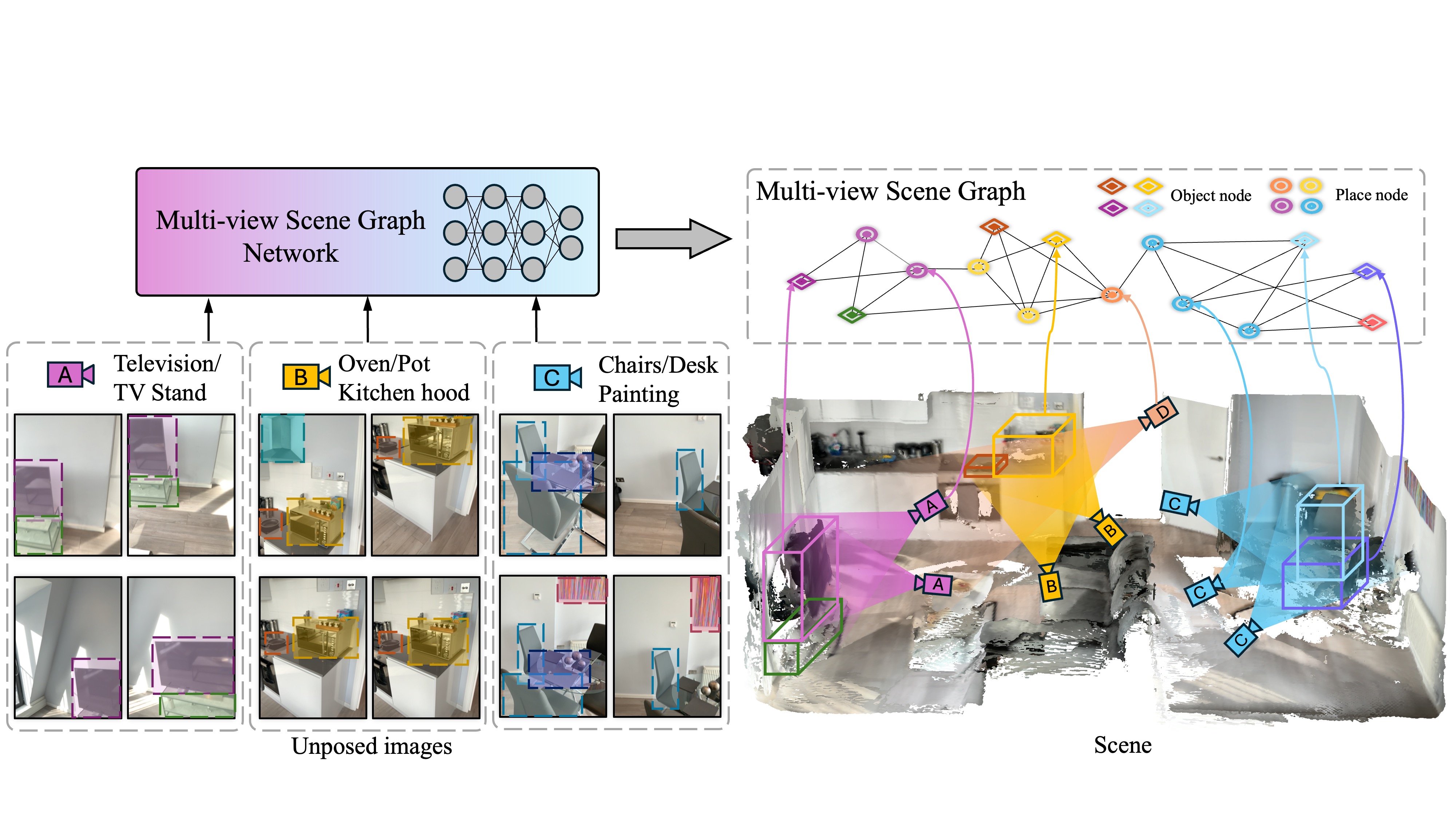
Juexiao Zhang, Gao Zhu, Sihang Li, Xinhao Liu, Haorui Song, Xinran Tang, Chen Feng NeurIPS 2024 arXiv / project page / code Build multiview place+object scene graph from unposed RGB image set. |
|
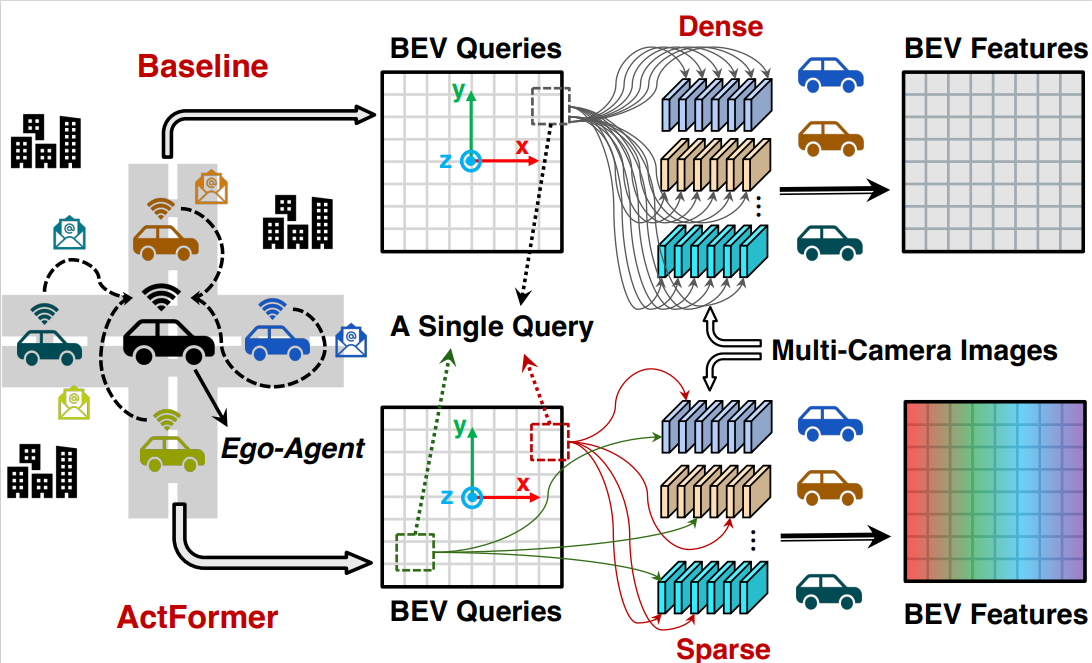
Suozhi Huang*, Juexiao Zhang*, Yiming Li, Chen Feng (* for equal contribution) ICRA, 2024 arXiv / project page / code A collaborative BEV Transformer for 3D object detection where each BEV query can actively select relevant cameras for information aggregation based on their pose information, instead of interacting with all cameras indiscriminately. |
|
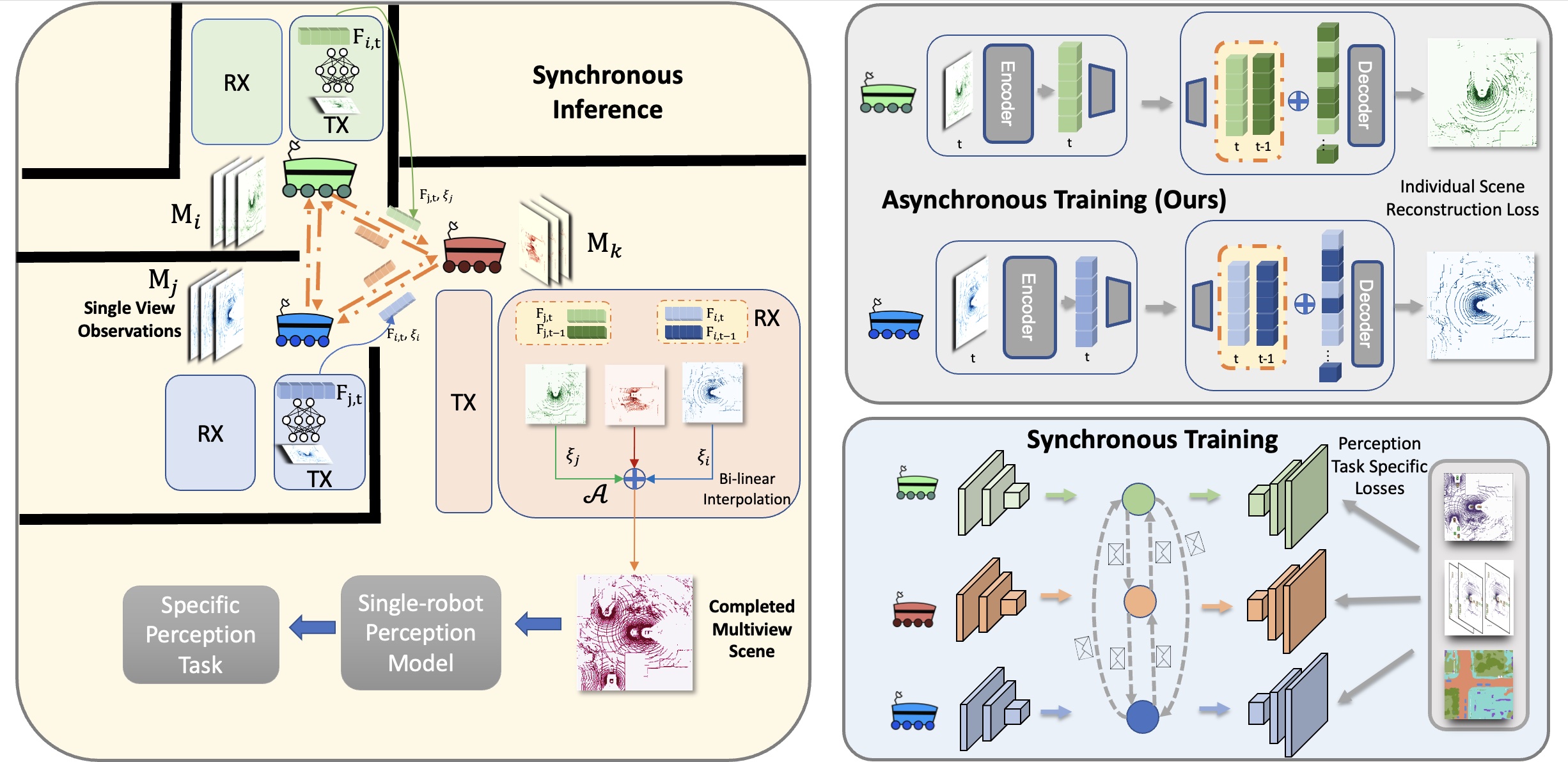
Yiming Li*, Juexiao Zhang*, Dekun Ma, Yue Wang, Chen Feng (* for equal contribution) CoRL, 2022 paper / project page / code A task-tgnostic framwork that allows asynchronous training for Collaborative perception. An autoencoder that amortizes communication in spatial-temporal domain. |
|
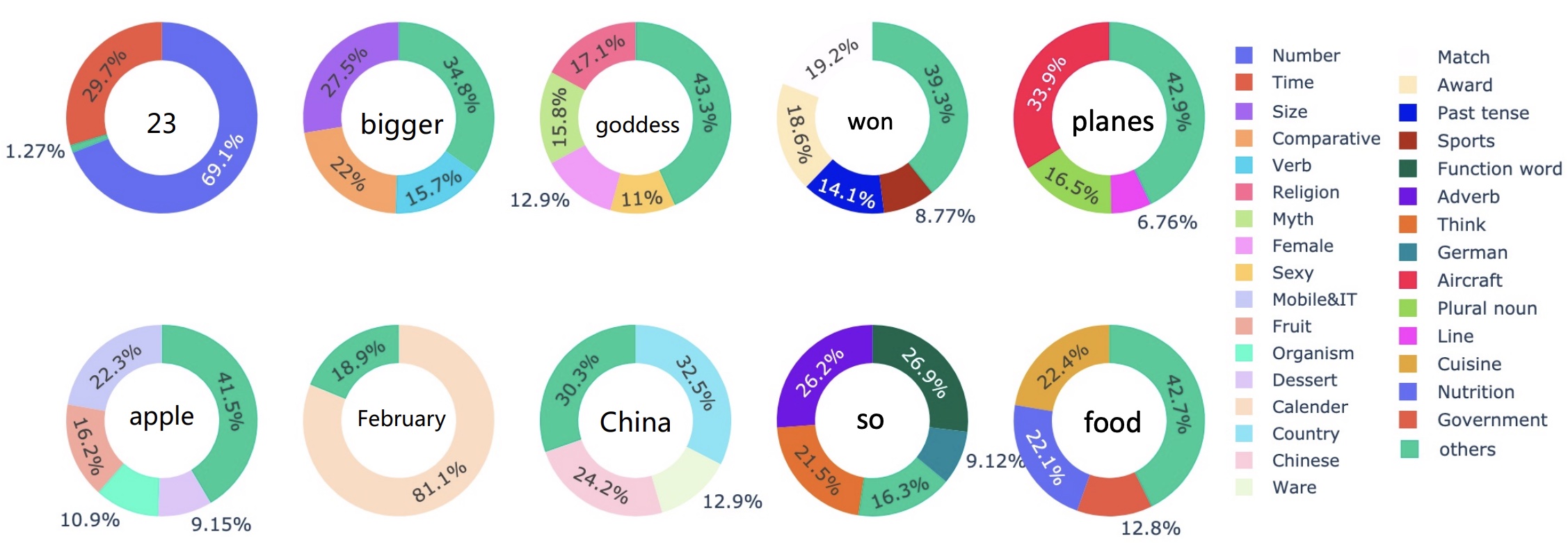
Juexiao Zhang*, Yubei Chen*, Brian Cheung, Bruno Olshausen (* for equal contribution) arXiv preprint arXiv:1910.03833 paper / code Decomposed word embedding via dictionary learning and spectral clustering and discover elemantary semantic factors. |
|
🤝 Collaborations with wonderful collaborators ✨. |
|
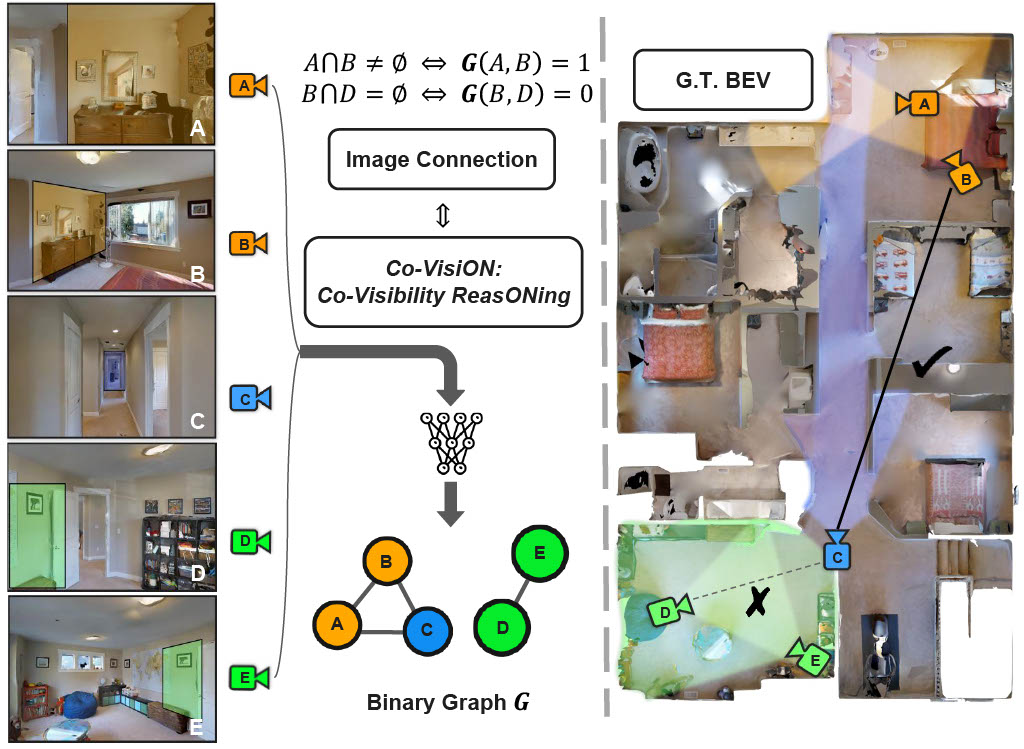
|
Chao Chen, Nobel Dang, Juexiao Zhang, Wenkai Sun, Pengfei Zheng, Xuhang He, Yimeng Ye, Taarun Srinivas, Chen Feng 2nd Human-inspired Computer Vision, ICCV 2025 Workshop, 2025 Outstanding Paper Award We reason about co-visibility relations within sparse indoor image sets to build complete scene understanding. |

|
Ruixuan Zhang, Beichen Wang, Juexiao Zhang, Zilin Bian, Chen Feng, Kaan Ozbay Accident Analysis & Prevention, 2025, NYC Vision Zero Award 2025 paper / news report Leverage Multimodal LLMs to interpret traffic accident videos and surface structured safety insights for roadway risk analysis. |
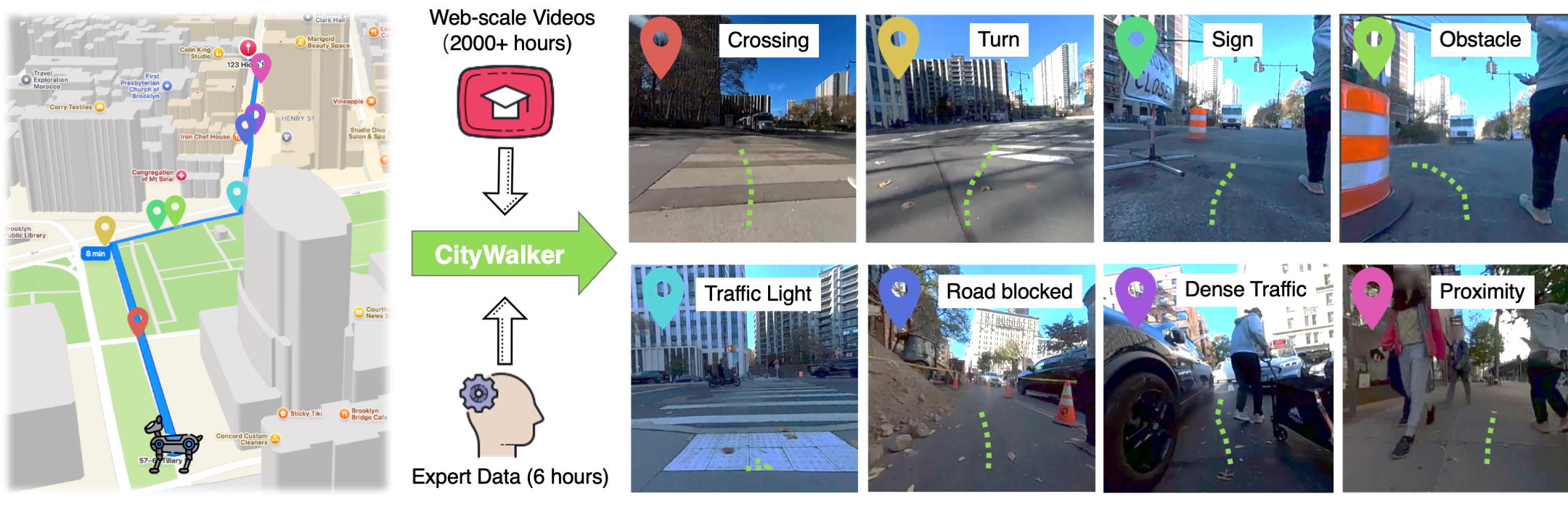
|
Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, Jone Abanes, Jing Zhang, Chen Feng, CVPR 2025 arXiv Project Page / Code / Data We leverage thousands of hours of online city walking and driving videos to train autonomous agents for robust, generalizable navigation in urban environments through scalable, data-driven imitation learning. |
|
Jing Zhang*, Irving Fang*, Hao Wu, Akshat Kaushik, Alice Rodriguez, Hanwen Zhao, Juexiao Zhang, Zhuo Zheng, Radu Iovita, Chen Feng (* for equal contribution) CVPR, 2024. Highlight project page / arXiv / code Paleoanthropology meets cutting-edge computer vision! |
|
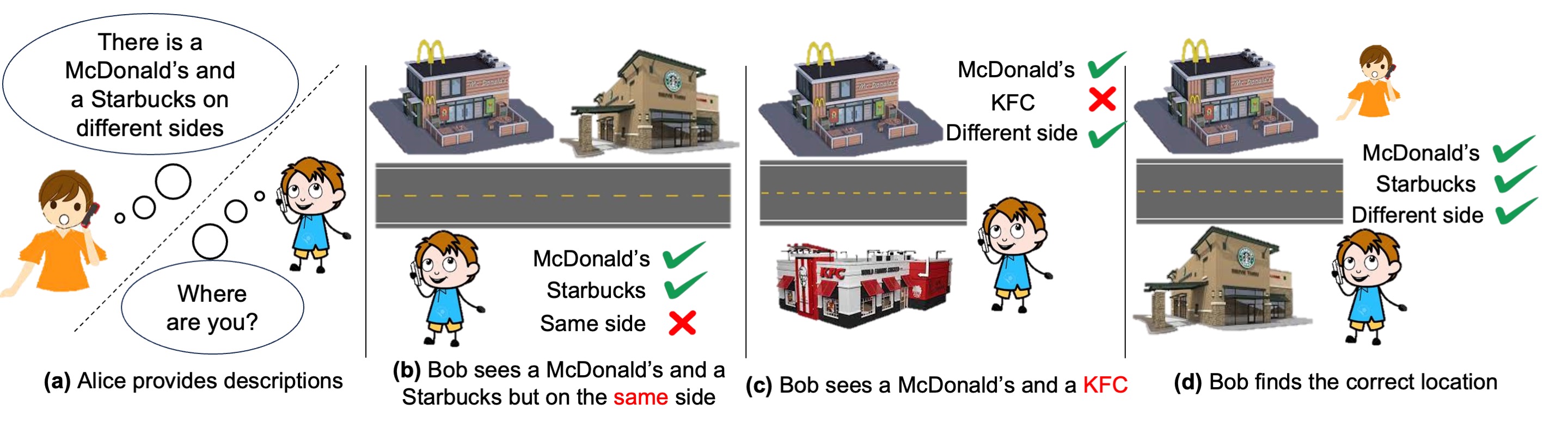
Zonglin Lyu, Juexiao Zhang, Mingxuan Lu, Yiming Li, Chen Feng Under review. arXiv / project page / code Can multimodal LLMs help visual place recognition? |
|
Reviewer NeurIPS, ICLR, CVPR, ICRA, IROS. |
|
National Scholarship in Tsinghua University, 2017
|
|
In my spare time, I enjoy playing soccer, making coffee, reading, photograph and travel. |
|
|